Serialization may be a quick and easy way of persisting a set of Java objects but it isn’t often a very space efficient one. Here we look at using compression with serialization to reduce the footprint of our saved objects and use JUnit Theories to test our mechanism over a range of object sizes.
For perhaps the majority of needs there are better ways to persist Java objects than Serialization, through which the raw data of an object-tree is written to a stream along with the type and version of each associated class. Serialization requires careful management if the persisted states must survive across application versions and its format does not lend itself to interoperability with non-Java technologies, isn’t human-readable and isn’t particularly machine-searchable. Serialized objects can also contain a lot of redundant or derived data if the class properties haven’t been appropriately marked up with transient keyword.
These deficiencies are only a problem if they’re a problem though. If you don’t need interoperability, version-portability or the ability to directly search and view persisted objects; when all you want is to quickly capture a set of Java objects for later recovery serialization really delivers. Nothing is going to make it simpler or easier for you.
But even with the judicious use of transients the size of the serialized representations for complex object hierarchies can get pretty huge. Fortunately it’s really easy to introduce compression into the serialization process and significantly cut the space needs for our serialized objects.
Simple serialisation
We’re going to test both raw and compressed serialization here, so let’s kick off with an interface which both our implementations can use:-
public interface ObjectSerializer<T extends Serializable> {
byte[] toBytes(T obj) throws IOException;
T fromBytes(byte[] obj)
throws IOException, ClassNotFoundException;
}
We don’t really need to make our ObjectSerializer generically typed but it does save us from having to cast results from our de-serialisation method and it adds a little extra type-safety to our app.
Next we’ll create a simple ObjectSerializer implementation that does no compression. We use a combination of ObjectOutputStream and ByteArrayOutputStream on the outbound leg, and their associated ObjectInputStream and ByteArrayInputStream on the inbound leg:-
public class SimpleSerlializer<T extends Serializable>
implements ObjectSerializer<T> {
@Override
public byte[] toBytes(T obj) throws IOException {
if(obj != null) {
try (ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos)) {
oos.writeObject(obj);
oos.flush();
return bos.toByteArray();
}
} else {
return null;
}
}
@SuppressWarnings("unchecked")
@Override
public T fromBytes(byte[] obj)
throws IOException, ClassNotFoundException {
if(obj != null) {
try (ObjectInputStream ois =
new ObjectInputStream(
new ByteArrayInputStream(obj))) {
return (T)ois.readObject();
}
} else {
return null;
}
}
}
We’re simply tying Object streams and ByteArray streams together here to convert between objects and serialised arrays of bytes.
Testing simple serialisation
At this stage let’s create a simple JUnit test to both validate our SimpleSerializer works correctly and also to exercise it over a range of data sizes.
Let’s kick off our test class with the definition of a test object which we’ll be serializing-
@RunWith(Theories.class)
public class ObjectSerlializerTest {
public static class MyData implements Serializable {
private static final long serialVersionUID = 1L;
private List<Integer> value = new ArrayList<Integer>();
public MyData() {
}
public void addValue(Integer i) {
value.add(i);
}
public boolean equals(Object o) {
return o instanceof MyData &&
Arrays.equals(value.toArray(),
((MyData)o).value.toArray());
}
}
// TODO
}
The type of the data fields to be serialized, along with their content, has a big impact on the size of the serialized state and will have a broader effect on the size of the compressed state since some data distributions are more compression-friendly than others. We don’t want to make it too easy here as we don’t want to generate results which flatter compression so we’ll fill our MyData class with a list of Integer objects which we’ll populate with set quantities of random values
You may notice we’re using @RunWith(Theories.class) for our test. JUnit Theories are a great, if not especially well documented way of repeating a test over a range of data values. They’re perfect for our needs here since we want to serialize a range of MyData instances and compare the speed and time for each with and without compression.
We’ll create a Theory test method which will run with a range of data sizes. It needs a size parameter which we need to annotate to specify the range of values to use:-
@Theory
public void testToBytes(@TestTo(max = 1000, step = 10) int size)
throws Exception {
// TODO
}
We now need to define our @TestTo annotation and provide a ParameterSupplier instance which will generate each test scenario to run:-
@Retention(RetentionPolicy.RUNTIME)
@ParametersSuppliedBy(TestToSupplier.class)
public @interface TestTo {
int max();
int step();
}
public static class TestToSupplier extends ParameterSupplier {
@Override
public List<PotentialAssignment> getValueSources(
ParameterSignature sig) {
TestTo annotation = (TestTo) sig.getAnnotation(TestTo.class);
List<PotentialAssignment> paramList =
new ArrayList<PotentialAssignment>();
for(int i = 0; annotation.max() >= i;
i += annotation.step()) {
paramList.add(PotentialAssignment.forValue(
"size", Integer.valueOf(i)));
}
return paramList;
}
}
So our testToBytes theory method is going to get executed 101 times in this example, for cases from 0 to 1000 Integer objects with an increment of 10 between each case (i.e. 0, 10, 20, 30 … 990, 1000). For each run it must populate a MyData instance with an appropriate number of random integers, serialize it (ideally several times to generate an average time), and then deserialize it to verify equivalence before finally recording the size of the serialized state and the time taken to create it:-
@Theory
public void testToBytes(@TestTo(max = 1000, step = 10) int size)
throws Exception {
final int TIMING_RUNS = 50;
ObjectSerializer<MyData> serialiser =
new SimpleSerlializer<MyData>();
// Create a test object with some random data
SecureRandom sec = new SecureRandom();
MyData toSerialise = new MyData();
for(int i = 0; size >= i; i++) {
toSerialise.addValue(sec.nextInt());
}
// Serialise TIMING_RUN times
long startTime = System.currentTimeMillis();
byte[] serialisedForm = null;
for(int i = 0; i TIMING_RUNS > i; i++) {
serialisedForm = serialiser.toBytes(toSerialise);
}
long endTime = System.currentTimeMillis();
// Validate the de-serialised object isn't the same, but matches
MyData deserialisedForm = serialiser.fromBytes(serialisedForm);
assertTrue(deserialisedForm != toSerialise);
assertTrue(deserialisedForm.equals(toSerialise));
// Log average time and serialised size for later use
System.out.println(size + ", " + serialisedForm.length + ", " +
(float)(endTime - startTime) / TIMING_RUNS);
}
Our test passes (always a good thing!) and reveals a consistent increment in serialized form size across each run:-
------------------------------------------------------- T E S T S ------------------------------------------------------- Running com.devsumo.playpen.java.serialisation.ObjectSerlializerTest 0, 246, 0.38 10, 346, 0.68 20, 446, 0.5 … 990, 10146, 0.48 1000, 10246, 0.94 Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 2.703 sec Results : Tests run: 1, Failures: 0, Errors: 0, Skipped: 0
Compressed serialization
Now it’s time to create the CompressedSerializer counterpart of our SimpleSerializer. All we need to do here is to introduce a GZIPOutputStream after the object is serialised on the way out, and a GZIPInputStream before the object is deserialised on the way back in:-
public class CompressedSerlializer<T extends Serializable>
implements ObjectSerializer<T> {
@Override
public byte[] toBytes(T obj) throws IOException {
if(obj != null) {
try (ByteArrayOutputStream bos = new ByteArrayOutputStream();
GZIPOutputStream zos = new GZIPOutputStream(bos);
ObjectOutputStream oos = new ObjectOutputStream(zos)) {
oos.writeObject(obj);
oos.flush();
zos.finish();
return bos.toByteArray();
}
} else {
return null;
}
}
@SuppressWarnings("unchecked")
@Override
public T fromBytes(byte[] obj)
throws IOException, ClassNotFoundException {
if(obj != null) {
try (ObjectInputStream ois =
new ObjectInputStream(
new GZIPInputStream(
new ByteArrayInputStream(obj)))) {
return (T)ois.readObject();
}
} else {
return null;
}
}
}
Testing and comparing compressed serialisation
Switching our test to use our CompressedSerializer class we can see we’re getting noticeably smaller serialised data sizes and noticeably longer run times; exactly what we’d expect to see when using compression:-
------------------------------------------------------- T E S T S ------------------------------------------------------- Running com.devsumo.playpen.java.serialisation.ObjectSerlializerTest 0, 228, 0.5 10, 293, 0.9 20, 351, 0.94 … 990, 5339, 3.26 1000, 5379, 3.58 Tests run: 1, Failures: 0, Errors: 0, Skipped: 0, Time elapsed: 10.435 sec Results : Tests run: 1, Failures: 0, Errors: 0, Skipped: 0
It’s particularly interesting to note that even our zero-size case, where we’re serializing only an empty list, gives us a compressed representation that’s smaller (albeit very slightly) than the uncompressed version. This suggests that the space overhead for a compressed stream is quite small and that we can save space even with very small objects.
These two charts show the results for all our test cases. We can see a pretty linear space saving in the region of 50% with a typical time overhead of 300-600%.
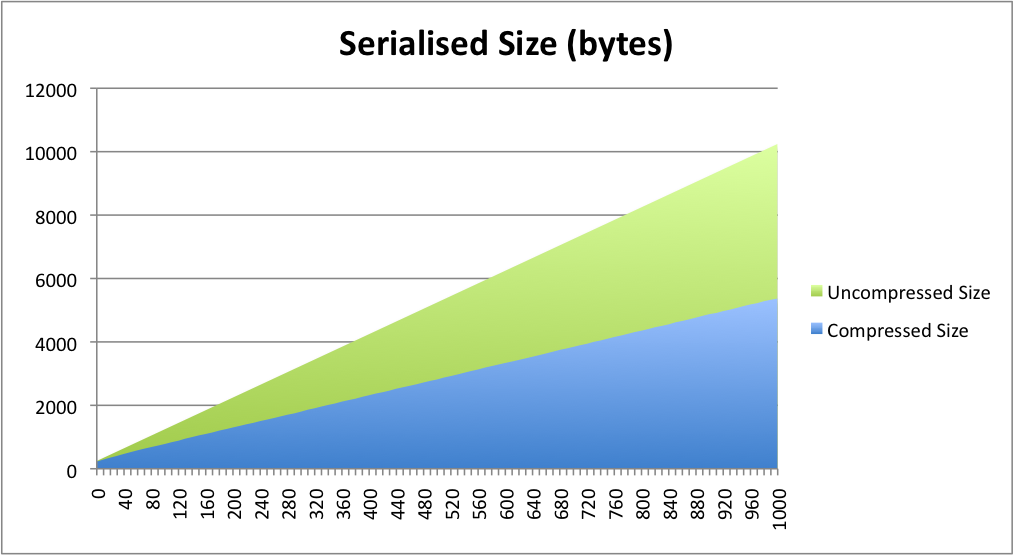
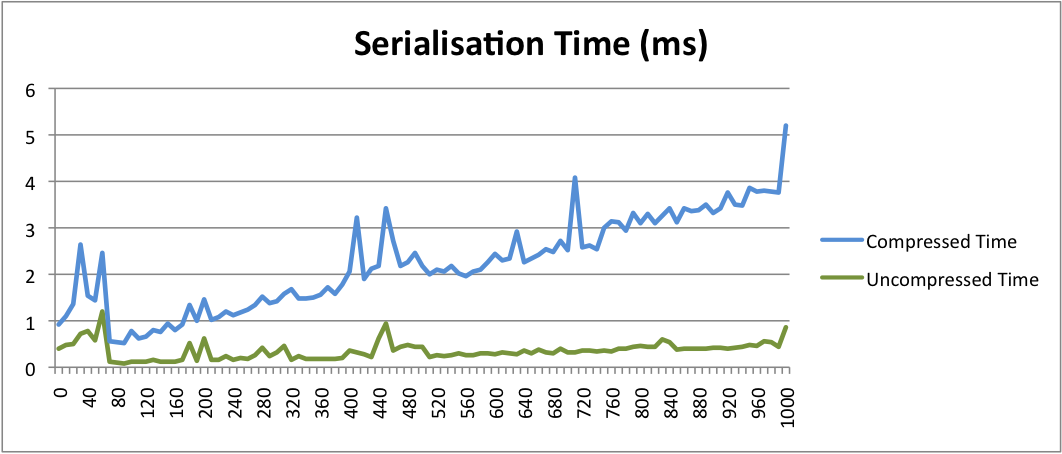
Obviously these results are specific to my test environment and particularly the nature of my test data. Less contrived data, such as text or uncompressed images, may well yield much bigger space savings. Both size and throughput constraints on whatever storage media we’re persisting the serialized representations to may also counterbalance the processing overhead.
The decision to use compressed serialization must be taken on a case-by-case basis, as indeed must the decision to use serialization at all as opposed to more scalable, portable and manageable technologies such as XML or ORM. If serialization is right for you though I hope we’ve shown here just how easy it is to add compression to reduce the footprint of your serialized objects.